教你如何跑 LLama3 模型 Demo
本文将介绍LLama 3,以及其框架,并一步步在 GPU 云服务上运行它。

LLama 3 模型已经开源了,感觉有一大波 Chinese -LLama 3 正在赶来的路上。如果你也想基于 LLama 3 训练一个自己的模型,那这篇教程就教你怎么来做。
在本文中,我们将介绍LLama 3,这是下一代最先进的开源大型语言模型。我们将了解LLama 3相对于LLama 2的进步。然后,我们将利用 Paperspace GPU 云的能力来深入探索,并尝试上手这个模型。因为 Paperspace 上有包括 H100、A100 等一系列 GPU 资源可以使用。
简单聊聊 LLama3
这里给还未了解 LLama 3 的开发者们,简要地介绍一下它。如果你已经是 AI 圈的老手,那么可以跳过这个章节。
Meta 最近宣布了LLama 3,这是下一代最先进的开源大型语言模型。
LLama 3 现在拥有 8B(80亿)和 70B(700亿)参数的语言模型。该模型已在各种任务中都有不俗的表现,并提供更好的推理能力。该模型已经开源,可供商业使用,并且开发者们可以在 AI 应用、开发者工具等方面进行创新。
LLama 3 有四个版本的大型语言模型(LLM)。这些模型有两种参数规模:8B 和 70B 参数,每种都有基础(预训练)和 instruct-tuned 版本。它们可以在不同类型的消费级硬件上平稳运行,并支持 8K(8000)token 的上下文长度。
- Meta-Llama-3-8b:基础 8B 模型
- Meta-Llama-3-8b-instruct:基于 8B 模型的 instruct-tuned 版本
- Meta-Llama-3-70b:基础 70B 模型
- Meta-Llama-3-70b-instruct:基于 70B 模型的 instruct-tuned 版本
LLama 3 的增强
最新的 8B 和 70B 参数的 LLama 3 模型,相比 LLama 2 有显著进步。有一些人表示,这是为大型语言模型设定了新的标准。由于更好的预训练和微调方法,它们已成为同类模型中的顶级存在。后训练增强中错误明显减少了,并提高了模型在推理、生成代码和遵循指令方面的性能。简而言之,LLama 3 比之前的很多模型都更先进、更灵活。下图是源自 Meta 官方的数据。
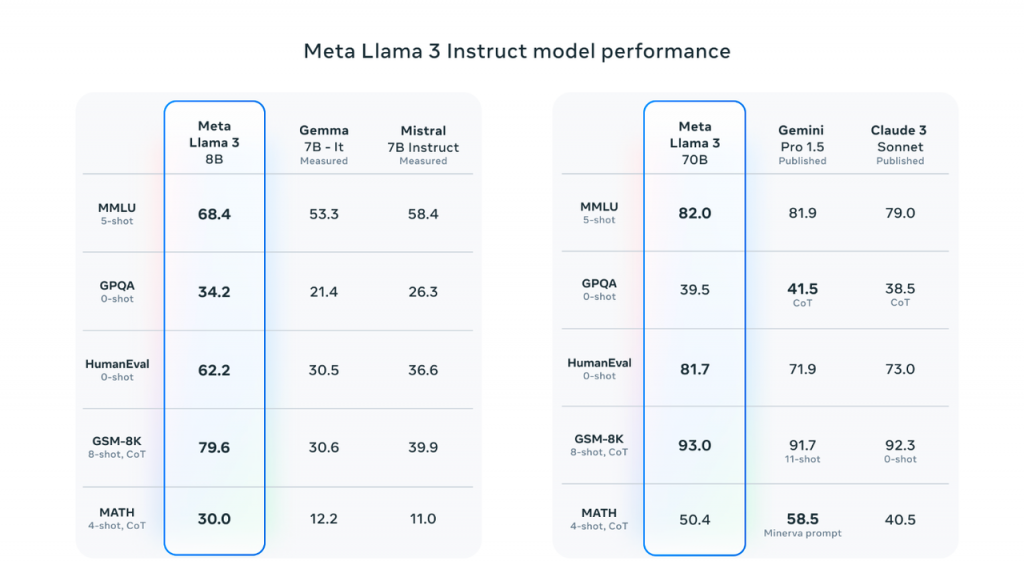
图:LLama 3 性能基准
在开发 LLama 3时,主要关注点是模型在现实生活情境中的优化。为此,他们创建了一个评估集,包含 1800 个 prompt,涵盖 12 个关键任务:寻求建议、编码和总结。此外,验证数据集也被禁止研发团队访问,以防止模型过拟合。将 LLama 3 与 Claude Sonnet、Mistral Medium 和 GPT-3.5 进行人工评估后,发现它在各种任务和场景中的结果都有不错的表现。
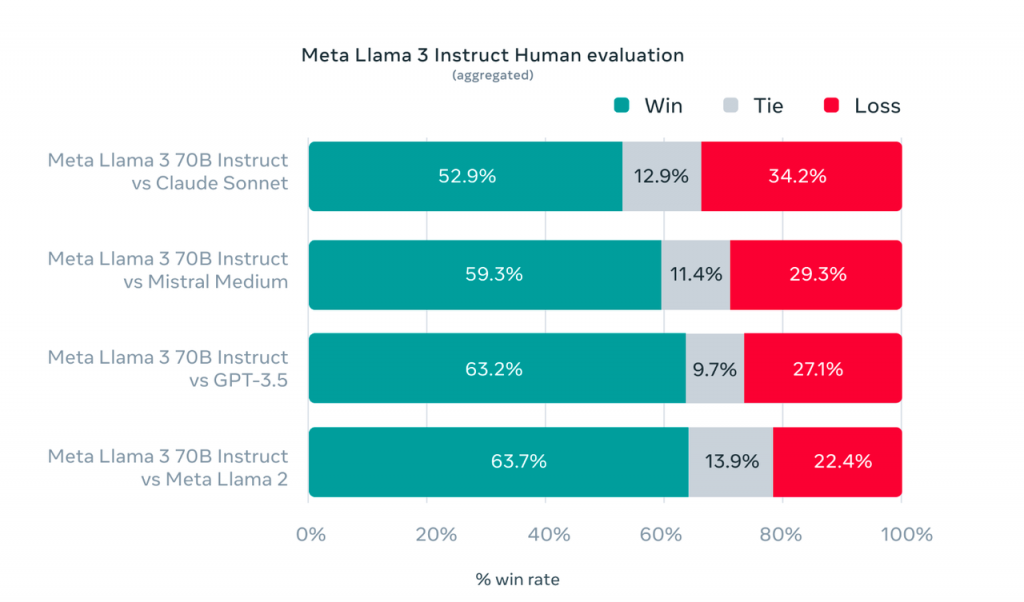
图表显示了人工评估在几个类别和提示下的结果
为了增强 LLama 3 的能力,Meta 专注于扩大预训练规模和完善后训练技术。
他们扩大了预训练规模,并制定了一系列详细的 scaling laws,以优化计算性能。令人惊讶的是,即使在训练了大量数据——高达 15T(万亿) 个 token 之后——其性能仍呈对数线性增长。结合使用各种并行化方法和定制的 GPU 集群,与LLama 2 相比,训练效率有效提高了三倍。
对于指令微调,Meta 考虑了不同的技术,如监督微调和偏好优化。此外,详细制定了训练数据和从偏好排名中学习,这有效提高了模型的性能,特别是在推理和编码任务中。这些改进使模型能够更好地理解和响应复杂任务。
模型架构
在设计 LLama 3 时,采用标准的解码器只有变换器架构,优化了编码效率和推理效率。与LLama 2相比,采用了有 128K 个标记词汇表的分词器,能更有效地对语言进行编码。此外,为了在推理期间让 LLama 3 模型更快,还引入了不同大小的分组查询注意力(GQA)。在训练期间,使用了 8192 个 token 的序列和一种掩码技术,以保持文档边界内的注意力。
LLama 3 在超过 15T token 的公开数据集上进行了预训练——比 LLama 2 使用的数据大 7 倍,而且代码量也大了 4 倍。该模型包含超过 5% 的非英语数据,涵盖 30 种语言,以便实现支持多语言。
为了保持在高质量的数据上进行训练,Meta 还构建了一系列数据过滤管道,还使用了启发式过滤器和文本分类器等,目的就是为了提高了模型性能。
运行 LLama 3 Demo
在我们开始之前,请确保在 huggingface.co 上获得对“meta-llama/Meta-Llama-3-70B”模型的访问权限。另外,我们在这里使用的是 Paperspace 平台上的 GPU,如果你手上还没有合适的 GPU 和机器,可以考虑这个平台。
要使用 Llama 3,我们首先要升级 transformers 包。
#upgrade the transformer package
pip install -U "transformers==4.40.0" --upgrade接下来,运行以下代码段。根据 Hugging Face 博客的提示,该模型通常需要大约 16GB 的 RAM,包括像 3090 或 4090 这样的 GPU。
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
pipeline("Hey how are you doing today?")如果你收到错误信息 “RuntimeError: cutlassF: no kernel found to launch!”,请尝试下面的代码,并再次运行该cell。
torch.backends.cuda.enable_mem_efficient_sdp(False)
torch.backends.cuda.enable_flash_sdp(False)生成的文本:“Hey how are you doing today? I hope you’re having a great day so far! I just”
在这里需要注意几件事情:
- 在我们的示例案例中,我们使用了’bfloat16’来加载模型。最初,Meta 使用的是’bfloat16’。因此,这是一种官方推荐的运行方式,可以确保最佳精度或进行评估。当然,你也可以尝试使用 float16,根据你硬件配置的情况,这可能会更快。
- 你还可以自动压缩模型,将其加载为 8 位或 4 位模式。在 4 位模式下运行需要的内存更少,使其能兼容许多消费级GPU 和性能较弱的 GPU。以下是如何以4位模式加载流水线的示例代码片段。
pipeline = transformers.pipeline(
"text-generation",
model="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
)LLama 3的未来
尽管当前的 8B(80亿)和 70B(700亿)参数模型给人留下了深刻印象,但 Meta 的工程师正在研究支持超过 400B(4000亿)参数的更大模型。这些模型仍在训练中。在未来几个月里,它们将更强的新功能,如多模态性、多语言对话能力、更长的上下文理解能力以及整体更强的能力。

Meta的LLama 3 最引人注目的一点就是开源。发布的基于文本的模型是LLama 3系列模型中的第一批。正如 Meta 所说,他们的主要目标是使 LLama 3 多语言和多模态,拥有更长的上下文支持,并持续改进核心大型语言模型(LLM)能力(如推理和编码)的整体性能。
我们迫不及待地想看看 GenAI 领域的下一个热点会是什么了。
最后,如果你正在计划训练自己的大语言模型,欢迎注册体验 DigitalOcean 旗下的 GPU 云服务 “Paperspace”,支持包括 H100、A100、4090 等多种 GPU,并预装 ML 框架。随时扩展,按需停止,只需按使用量付费。
如果需要预约更多 GPU 资源或希望了解方案详情,可以与 DigitalOcean 中国区独家战略合作伙伴卓普云咨询。
卓普云官网:https://www.aidroplet.com/
Paperspace 官网:http://www.paperspace.com/