手把手教学:MosaicML 模型在 H100 上的预训练与调优
MosaicML 的名字应该很多搞 AI 的人都知道。他们推出的 MPT 系列模型,其中 70 亿参数版在 […]

MosaicML 的名字应该很多搞 AI 的人都知道。他们推出的 MPT 系列模型,其中 70 亿参数版在性能测试中与 LLaMA 打个平手。
H100 应该也是无人不知吧?虽然现在性能最强的,应该是 NVIDIA 在“AI 春晚”发布的 B200。不过,现在大多数人能接触到的应该还是 H100。
OK,那我们来用这一篇教程,来讲讲使用 H100 进行 MosaicML 模型的预训练和调优的过程。
首先,我们与大家一样,也买不到那么多的 H100。所以,我们会借助云端的力量来解决算力、存储等一系列问题。否则,整个预训练和 finetuning 的过程会用很多天才能完成。
由于 DigitalOcean 已经支持 H100 GPU。所以我们在这里会使用 DigitalOcean 的多节点机器和 Paperspace 上的 H100 GPU 做这次大型语言模型(LLM)的端到端预训练和微调。用到的是 4个节点,每个节点配备 H100×8 GPU,可提供高达 127 petaFLOPS 的计算能力,让我们能够在短短几小时内对全尺寸的最先进 LLM 进行预训练、微调。本次选择的模型是 MPT-30B。
这里先简单介绍一下使用的工具,DigitalOcean 是一家已经上市的云服务平台,每个新注册的用户都会有一定的免费额度,而且它本身价格也比其它云服务大厂亲民很多。Paperspace 是 GPU 云服务平台,在去年也被 DigitalOcean 收购了。该平台目前提供了包括 H100、A100 等多种 GPU。使用 GPU 云服务,总比自己买 GPU 然后搭建机器要方便得多。当然,你可以选择购买 GPU 自建服务器,或找GPU 租赁平台,但是 GPU 云服务是相对最方便的一个选项,他们三者之间的对比我们在这里就不赘述了。
获取 H100 的方式很简单。
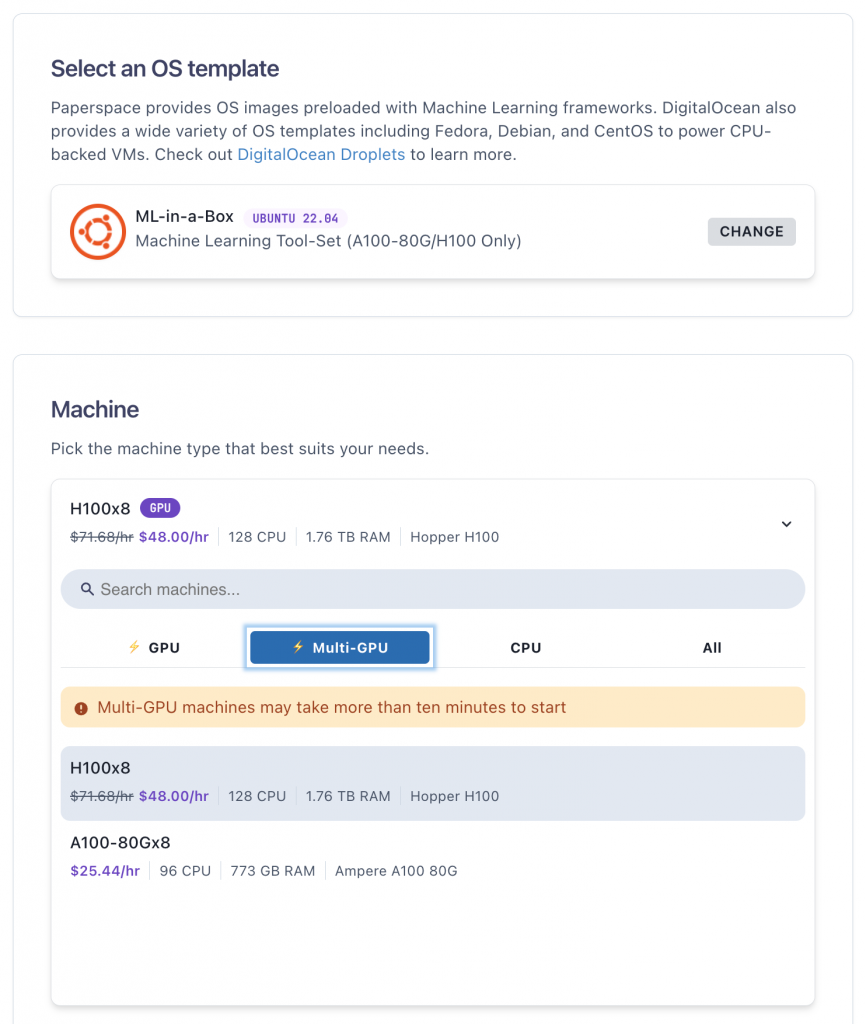
DigitalOcean 旗下的 Paperspace 已经为开发者提供 NVIDIA H100 GPU 的服务,包括 H100×1 或 H100×8 的配置。
Paperspace 的云服务简化了 GPU 的配置和使用过程,而且通过该平台提供的 ML-in-a-Box 模板功能为开发者提供现成的 AI/ML 软件堆栈。
在 Paperspace 的后台,只需要在界面中点击以下选项,即可开始使用 H100×8。不过,如果你使用的量比较大,需要在该平台上预约一下。具体如果还有其他疑问和需求,比如想要更多 GPU 资源,可以扫描下方二维码,直接找DigitalOcean官方的中国区技术支持。
MosaicML MPT 模型

MosaicML 维护的 LLM Foundry GitHub 仓库,提供了 MPT 系列模型。他们持续以在实践中端到端可用的设置,提供最新版本的开源LLM。
这里我们重点关注其中两个模型:
- MPT-760m 用于预训练:MPT 系列包含不同大小的模型,它们的命名基于参数数量(m代表百万,b代表十亿):125m、350m、760m、1b、3b、7b、13b、30b、70b。我们选择760m进行预训练,是因为它的大小适中,不需要等待数天或数周来完成训练。(较大的模型不仅尺寸更大,还需要更多的批次进行训练。MosaicML的原始7B模型预训练在440个A100-40G GPU上进行了9.5天,花费了20万美元。)
- MPT-30B 用于微调:通常,通用的 LLM 在回答问题时,更像是继续聊天而不是回答问题。MPT-30B 模型经过调整,能比基础模型更好地更流畅地回答问题。我们选择300亿参数的模型是因为(a)它代表了大多数企业想要调整以解决其实际问题的完整大小的模型,(b)在 LLM Foundry 上有针对 30B 的优化 YAML。最终模型应该与 MosaicML 在 Hugging Face 上提供的 MPT-30B-Instruct 模型相似。
重要的是,这些模型是开源的,它们也允许商业使用,这意味着你可以把他们用在你的业务上。
端到端的过程
这是大家经常说的人工智能的端到端流程,总共有 11 步,它包括了从商业问题的产生到实现商业价值:
- 商业问题
- 数据起源
- 数据收集
- 数据存储
- 数据准备
- 模型训练
- 模型转换为推理
- 推理/部署
- 部署到生产环境
- 监控
- 获取商业价值的接口
那么,我们这篇文章真的会做到一个端到端的训练吗?
事实上,我们并没有将这次训练的模型投入到盈利的产品中,但我们确实完成了大部分步骤。最重要的是,虽然在这篇博文中我们没有完成这 11 个步骤,但在 DigitalOcean 的 Paperspace 平台上,可以跑完这些步骤。
我们简单讲一下,以上每一步,我们会做什么,即大家会阅读到的内容。
第一步,商业问题,是我们希望从我们的数据开始,从头开始预训练一个大语言模型(LLM),以便我们拥有完全的控制权,然后微调另一个模型,以便更好地回答我们用户的问题。由于数据已经存在于线上,因此这里不执行步骤2。对于步骤3到步骤5,我们正在下载相当大的数据,将其存储起来,以便高效地访问,而不会让它成为H100 GPU的瓶颈,并执行诸如分词之类的准备工作。步骤6是模型预训练或微调,我们正在通过 GitHub 仓库的代码和 YAML 设置执行此操作。同样,步骤7将训练得到的检查点模型转换为更适合部署的格式。(进行推理的模型不需要来自训练的所有信息,例如优化器状态,因此格式可以更小。)然后,步骤8是我们将用户提示传递给模型并查看其响应。
步骤9到步骤11可以完成,但我们在这里并不尝试。首先,我们需要将步骤8中使用的模型放在一个 endpoint 上,例如通过 Paperspace Deployments 让它进入云端,成为一个 API 供后续的业务进行调用,甚至之后的产品化。然后,可以使用诸如 Arize 之类的监控软件来查看模型在线时的状态以及其行为是否正确。最后,步骤11将通过指向模型的Web应用提供一个窗口,让非技术人员也可以与之交互。
设置
OK,具体了解过我们这次端到端流程,接下来让我们看看如何实现它。
首先,我们将详细介绍如何在 DigitalOcean 的 Paperspace 上设置模型,进行训练。然后,我们将做预训练和微调,最后是推理和部署。
这些部分相当长,但它们真实地反映了在大规模运行 LLM 时所需采取的步骤,以及您在运行自己的LLM时可能采取的步骤。
我们开始吧!
注册平台
要运行这两个模型并访问H100 GPU,需要注册一个 Paperspace 账号。作为注册过程的一部分,你将被引导申请启动 H100 。
H100机器
在Paperspace 的后台(即 Paperspace Core)中启动时,系统会通知你需要一个专用网络。这看似不太方便,因为当所有机器都需要它时,必须手动添加,但在Paperspace 上,操作非常简单:只需点击“添加专用网络”,选择一个名称,然后从“选择网络”下拉菜单中选择它即可。
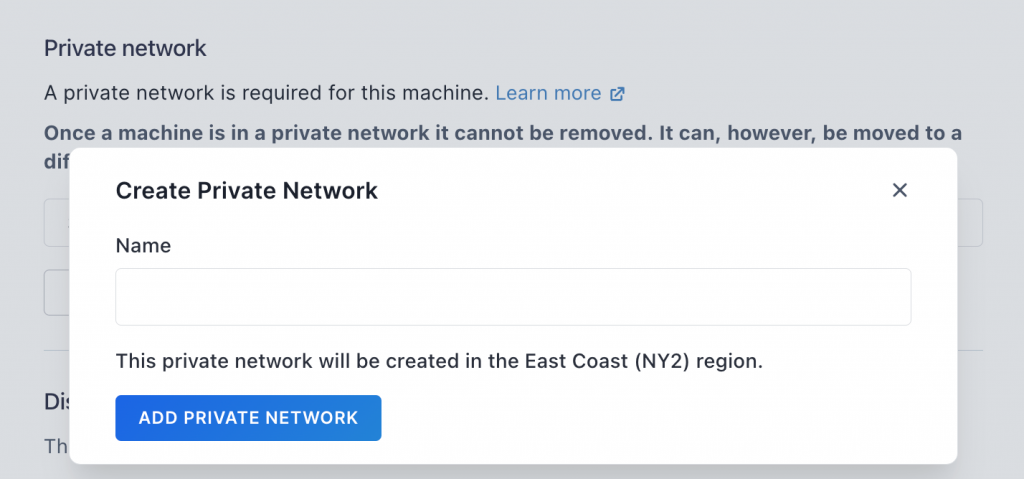
对于多节点(multinode)任务,机器之间需要相互通信,因此无论如何都需要一个专用网络。我们将在下文中使用这个网络,并访问共享存储来存储我们的数据和模型。
访问存储用的主机还需要一个SSH密钥。磁盘大小应从默认的 100 GB 增加到 1-2 TB。
其他选项,如动态 IP,可以保留其默认设置。NVLink 是默认启用的。
通过 SSH 从本地计算机的终端访问主机的动态IP,例如
ssh paperspace@123.456.789.012你可以在后台详细信息页面上查看机器的 IP。在 Mac 上,可以直接用 iTerm2,其它任何带有 SSH 功能的终端都应该可以。访问成功后,你应该能看到机器的命令行。
如果即计划进行多节点人物,请重复上述步骤,以创建足够的节点数量。
共享存储
Paperspace 的共享存储提供了对大型文件(如数据和模型)的高性能访问,这些文件用户不希望直接存储在机器上,或者需要在多台机器上共享。
共享存储最多可以存储 16TB 的数据,而机器自身硬盘最多能存 2TB。
设置一个共享存储需要一些手动步骤,但这些步骤很简单。
(1) 在 Paperspace Core (也就是后台)中,转到“Drives” Tab 页,点击“Create”,然后会出现一个包含硬盘详细信息的浮窗。填写上名称、大小、区域和专用网络。名称是任意的,对于大小,我们推荐 2TB 或更多,对于区域,可以使用你在上文创建的机器所在的区域,同样对于专用网络也是如此。

(2) 在你的机器的终端中,编辑 /etc/fstab 文件,添加刚刚创建的 Drive 的信息,例如:
sudo vi /etc/fstab验证信息会是:
//10.1.2.3/stu1vwx2yz /mnt/my_shared_drive cifs
user=aBcDEfghIjKL,password=<copy from GUI>,rw,uid=1000,gid=1000,users 0 0在 Paperspace 后台的“Drives” Tab 页中,你可以查看存储磁盘的所有信息。
注意:在后台中,网络地址用反斜杠\表示,但在/etc/fstab中,你需要将其写为正斜杠/。
(3) 使用以下命令挂载共享磁盘:
sudo mkdir -p /mnt/my_shared_drive
sudo chown paperspace:paperspace /mnt/my_shared_drive
mount /mnt/my_shared_drive你可以使用 df -h 命令来检查磁盘是否可见,它应该会显示在输出行的某一行中。
如果你正在使用多节点,则需要在所有机器上重复编辑 /etc/fstab 和挂载共享存储磁盘。
请注意,原则上,共享磁盘也可以是远程的,例如对象存储,但我们在本文中并不会探讨这种设置,大家需要自己尝试。
MosaicML 的 Docker 容器
现在我们已经设置了机器和共享磁盘,接下来需要设置 MosaicML LLM Foundry。
为了确保我们的模型运行环境稳定且可复现,我们遵循他们的建议,使用他们提供的Docker镜像。
他们提供了多个镜像选择,我们选择了带有最新版本的 Flash Attention的镜像:
docker pull mosaicml/llm-foundry:2.1.0_cu121_flash2-latest要运行容器,我们需要将共享磁盘绑定挂载到容器上,以便容器可以找到它,对于多节点,还需要传递各种参数,以便使用完整的 H100 GPU fabric:
docker run -it \
--gpus all \
--ipc host \
--name <container name> \
--network host \
--mount type=bind,source=/mnt/my_shared_drive,\
target=/mnt/my_shared_drive \
--shm-size=4g \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--device /dev/infiniband/:/dev/infiniband/ \
--volume /dev/infiniband/:/dev/infiniband/ \
--volume /sys/class/infiniband/:/sys/class/infiniband/ \
--volume /etc/nccl/:/etc/nccl/ \
--volume /etc/nccl.conf:/etc/nccl.conf:ro \
<container image ID>在这个命令中,-it 是常用的容器设置,用于获取交互性;–gpus 是因为我们使用的是NVIDIA Docker(随我们的机器ML-in-a-Box模板提供);–ipc 和–network 有助于网络功能正确运行;–mount 是绑定挂载,以便在容器内将共享底盘视为 /mnt/my_shared_drive;–shm-size 和–ulimit 确保我们有足够的内存来运行模型;而–device 和–volume 用于设置 GPU 结构。
你可以通过在主机上运行 docker images 命令来查看你的容器的镜像 ID,而你的容器名称是任意的。我们使用了包含日期的名称,例如:
export CONTAINER_NAME=\
`echo mpt_pretraining_node_${NODE_RANK}_\`date +%Y-%m-%d_%H%M-%S\``出于版本控制的目的,NODE_RANK 对应于网络上的不同节点,其值可以是 0、1、2 等。
如果你要重启现有的容器,而不是创建新容器,可以使用 docker start -ai <container ID> 命令,其中容器ID可以通过 docker ps -a 命令查看。这将让你回到容器的命令行界面,与新创建容器时的情况相同。
关于容器设置的最后一点要说明的是,Paperspace 后台的 ML-in-a-Box 模板包含了一个用于NVIDIA Collective Communications Library(NCCL)的配置文件,该文件有助于H100和我们的3.2 Tb/s节点更好地数据交互。这个文件位于/etc/nccl.conf,内容如下:
NCCL_TOPO_FILE=/etc/nccl/topo.xml
NCCL_IB_DISABLE=0
NCCL_IB_CUDA_SUPPORT=1
NCCL_IB_HCA=mlx5
NCCL_CROSS_NIC=0
NCCL_SOCKET_IFNAME=eth0
NCCL_IB_GID_INDEX=1这个文件已提供了,无需用户进行修改。
与共享存储磁盘一样,如果你正在运行多节点任务,那么这个过程需要在每个节点上重复操作一遍。
我们建议在启动容器之前,使用 tmux -CC 启动一个tmux会话。这有助于防止因网络断开而导致训练终止。在Mac上,iTerm2 本身就支持 tmux。更多详细信息,可以查看这个文档。
在容器中设置GitHub 仓库
进入容器后,就可以通过克隆 GitHub 仓库,并将其安装为 package 来设置代码了。根据 LLM Foundry 的 readme 文件,步骤如下:
git clone https://github.com/mosaicml/llm-foundry.git
cd llm-foundry
pip install -e ".[gpu]"在我们的机器上,我们首先安装了一个编辑器(apt update; apt install -y vim),更新了 pip(pip install –upgrade pip),并记录了我们使用的存储库的版本(cd llm-foundry; git rev-parse main)。
还有一些可选步骤,包括为 H100s 安装 XFormers 和 FP8(8 位数据类型)支持:pip install xformers 和 pip install flash-attn==1.0.7 –no-build-isolation,以及 pip install git+https://github.com/NVIDIA/TransformerEngine.git@v0.10。我们实际上是在没有这些优化的情况下生成了我们的结果,但它们是可选的优化选项。
记录管理
这个仓库通过 Python 脚本来调用代码以准备数据、训练模型和运行推理。因此,原则上它的运行很简单,但为了以运行起来更方便,我们还需要一些额外的步骤:
- 创建一些目录:数据、模型检查点、用于推理的模型、YAML文件、日志、每个节点的子目录、预训练或微调任务、各种运行,以及其他如包含提示文本的文件。
- 启用Weights & Biases日志记录:这不是严格必需的,也可以集成其他库,如 TensorBoard,但这会自动绘制一些有用的指标样本,以提供关于我们运行的信息。这些指标包括训练期间的GPU使用情况和模型性能。这需要Weights & Biases账户。
- 环境变量:也不是严格必需的,但很有用。随着新基础设施在发布前变得更加可靠,NCCL_DEBUG=INFO 的需求有所减少,但我们仍然设置它。如果使用 Weights and Biases进行日志记录,则需要将 WANDB_API_KEY 设置为你的API密钥的值,以便在不进行手动交互步骤的情况下启用日志记录。我们还设置了一些其他变量,以简化在多节点上引用各种目录的命令,如下所示。
为了多节点运行预训练和微调,最少还需要一组目录:
/llm-own/logs/pretrain/single_node/
/llm-own/logs/finetune/multinode/
/llm-own/logs/convert_dataset/c4/
$SD/data/c4/
$SD/yamls/pretrain/
$SD/yamls/finetune/
$SD/pretrain/single_node/node0/mpt-760m/checkpoints/
$SD/pretrain/single_node/node0/mpt-760m/hf_for_inference/
$SD/finetune/multinode/mpt-30b-instruct/checkpoints/
$SD/finetune/multinode/mpt-30b-instruct/hf_for_inference/其中,SD是我们共享存储的位置,NODE_RANK对于不同的 H100×8 节点来说,可以是0、1、2等。/llm-own是任意的,只是在容器中放置目录的一个位置。
这些命令看起来可能有些长,但实际上我们在这个博客文章中展示的模型和变化比实际运行的要多。你可以使用mkdir -p命令同时创建子目录和父目录。
准备开始!
现在设置已经完成,我们可以开始准备数据→模型训练→推理+部署了。
MPT-760m 预训练
现在我们已经按照上一节的步骤设置好环境,我们的第一个运行是模型预训练。这是针对 MPT-760m 的。
我们在单节点和多节点上都运行了这个。这里我们展示单节点的情况,下面在MPT-30B微调时我们将展示多节点的情况。
获取数据

对于大型语言模型(LLM)的预训练,数据量是巨大的:Hugging Face 上的 C4 数据集是基于 Common Crawl 数据集进行 LLM 预训练的,包含超过两百万行数据。
通常来讲,数据的一个 row 看起来像这样:
{
'url': 'https://klyq.com/beginners-bbq-class-taking-place-in-missoula/',
'text': 'Beginners BBQ Class Taking Place in Missoula!\nDo you want to get better at making delicious BBQ? You will have the opportunity, put this on your calendar now. Thursday, September 22nd join World Class BBQ Champion, Tony Balay from Lonestar Smoke Rangers. He will be teaching a beginner level class for everyone who wants to get better with their culinary skills.\nHe will teach you everything you need to know to compete in a KCBS BBQ competition, including techniques, recipes, timelines, meat selection and trimming, plus smoker and fire information.\nThe cost to be in the class is $35 per person, and for spectators it is free. Included in the cost will be either a t-shirt or apron and you will be tasting samples of each meat that is prepared.',
'timestamp': '2019-04-25T12:57:54Z'
}LLM Foundry 提供了一个脚本来下载和准备数据。我们使用以下命令来调用它:
time python \
/llm-foundry/scripts/data_prep/convert_dataset_hf.py \
--dataset c4 \
--data_subset en \
--out_root $SD/data/c4 \
--splits train val \
--concat_tokens 2048 \
--tokenizer EleutherAI/gpt-neox-20b \
--eos_text '<|endoftext|>' \
2>&1 | tee /llm-own/logs/convert_dataset/c4/convert_dataset_hf.log该命令包含在 time … 2>&1 tee <logfile> 中,以便我们可以将终端的标准输出和错误输出捕获到日志文件中,并记录运行所花费的时间。我们在整个工作中都使用了这个简单的 time … tee 方法。当然,你也可以选择不用这个方法。
预处理过程不使用多节点或 GPU,但如果有良好的网络速度用于下载,该步骤可以在大约 2-3 小时内作为一次性步骤运行,因此使用像 DALI 或 GPUDirect 这样的工具将这一步骤优化到 GPU上,可用也可不用。
该脚本将下载的数据转换为 MosaicML StreamingDataset 格式,该格式更适合大规模分布式模型的运行。生成的文件集包括 20850 个 shards,这些 shards 位于 /mnt/my_shared_drive/data/c4/train/shard.{00000…20849}.mds 中,以及一个 JSON 索引文件中,另外还有 21 个 shards 作为验证集,位于 val/目录中。磁盘上的总大小约为 1.3TB。
YAML 文件
数据准备好之后,我们需要设置所有描述模型及其训练参数的正确值。所幸,仓库已经为预训练和微调设置了一系列参数。它们是 YAML文件格式的。
对于 MPT-760m 模型,我们使用这个 YAML 文件中的值,并保留默认值,除了以下情况:
data_local: /mnt/my_shared_drive/data/c4
loggers:
wandb: {}
save_folder: /llm-own/nick_mpt_8t/pretrain/single_node/node0/\
mpt-760m/checkpoints/{run_name}我们指向共享存储磁盘上的数据,取消注释 Weights & Biases 日志记录,并将模型保存到包含运行名称的目录中。该名称可由环境变量 RUN_NAME 设置,YAML 文件默认会获取该变量。为了版本控制,我们按照与上面容器名称类似的方式为其添加日期。
在单个节点上运行允许我们保留默认的每 1000 个批次将检查点保存到 save_folder 的设置,因为对于760m模型来说,检查点文件并不特别大。我们将它们保存到机器的驱动器上,以避免共享驱动器上符号链接的问题——请参见下面的MPT-30B微调部分。如果需要,它们可以在运行后移动到共享驱动器上。
在一篇关于MPT的博客文章中,在MPT-7B的微调运行部分详细讨论了这些模型的其他许多YAML参数的含义。大家如果感兴趣,可以跳转阅读。
进行预训练
数据和模型参数设置好后,我们就可以开始完整的预训练运行了:
time composer \
/llm-foundry/scripts/train/train.py \
/llm-own/yamls/pretrain/mpt-760m_single_node.yaml \
2>&1 | tee /llm-own/logs/pretrain/single_node/\
{$RUN_NAME}_run_pretraining.log这个命令使用 MosaicML 开源的 composer 库,它基于 PyTorch的,它将使用此节点上的所有 8xH100 GPU。可以向命令传递参数,但我们已将它们全部封装在 mpt-760m_single_node.yaml YAML 文件中。
与上面一样,time … tee 是我们自己的加的,大家也可以选择不加它,因此该命令在原则上已简化为非常简单的 composer train.py <YAML文件>。
预训练运行结果
使用一个 H100×8 节点,进行 MPT-760m 预训练大约需要 10.5 小时才能完成。(而在 2 个节点上进行多节点训练时,它可以在不到 6 小时内完成。)
我们可以通过查看 Weights & Biases 自动生成的图表来查看训练的一些情况。
训练过程中可以通过多种方式来判断模型性能的提升,这里默认是通过 损失(loss)、交叉熵和困惑度(perplexity)来衡量的。对于交叉熵,我们可以看到其值与训练过程中达到的批次数量之间的关系,从0到29000:
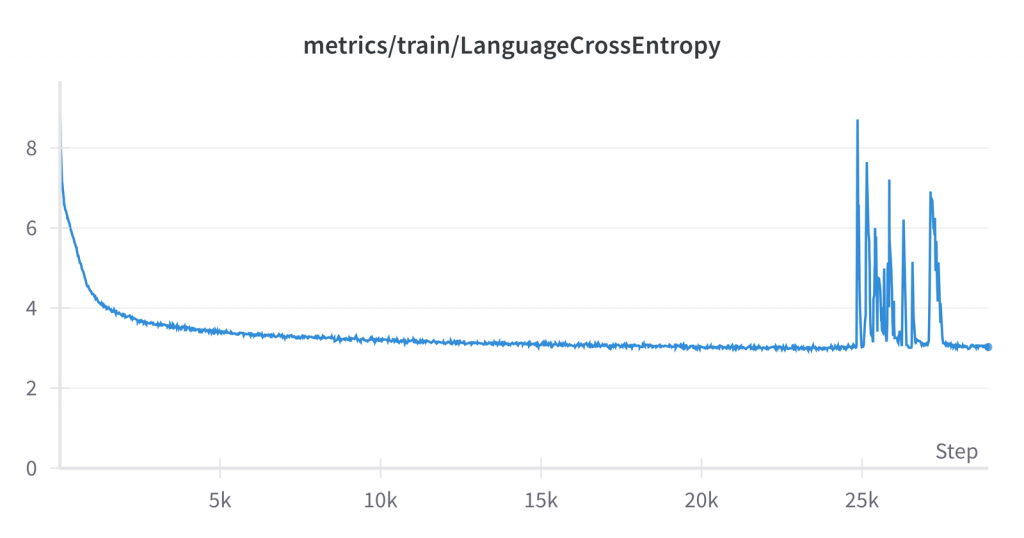
图:熵值越低越好
峰值在大约 25k-28k 处,这里有些奇怪,但似乎并不影响最终结果,该结果反映了曲线在大约3的值附近逐渐平坦。损失和困惑度的图表形状相似,在evaluation set上的模型图表也是如此。
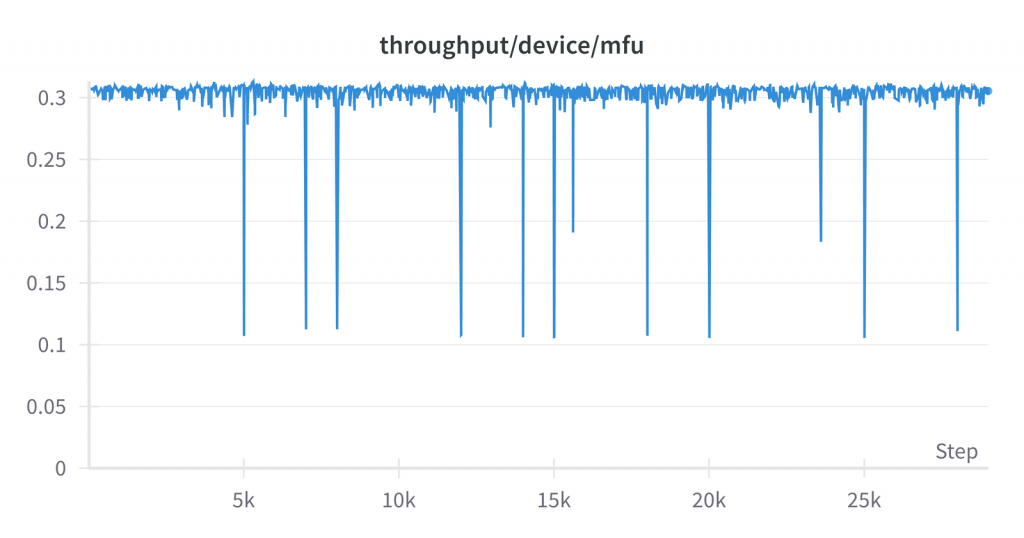
图:MFU与批次数量对比
模型浮点运算次数利用率(MFU)显示了 GPU 的使用效率。我们看到,除了偶尔的下降外,它整体上是稳定的,并略高于 0.3。理论上完美的值是1,而在实践中,经过高度优化的运行可以接近0.5。因此,我们模型的详细设置可能还有一些改进空间,但差距并不太大。每秒处理的 Token 数(吞吐量)的图表看起来相似,约为4.5e+5。
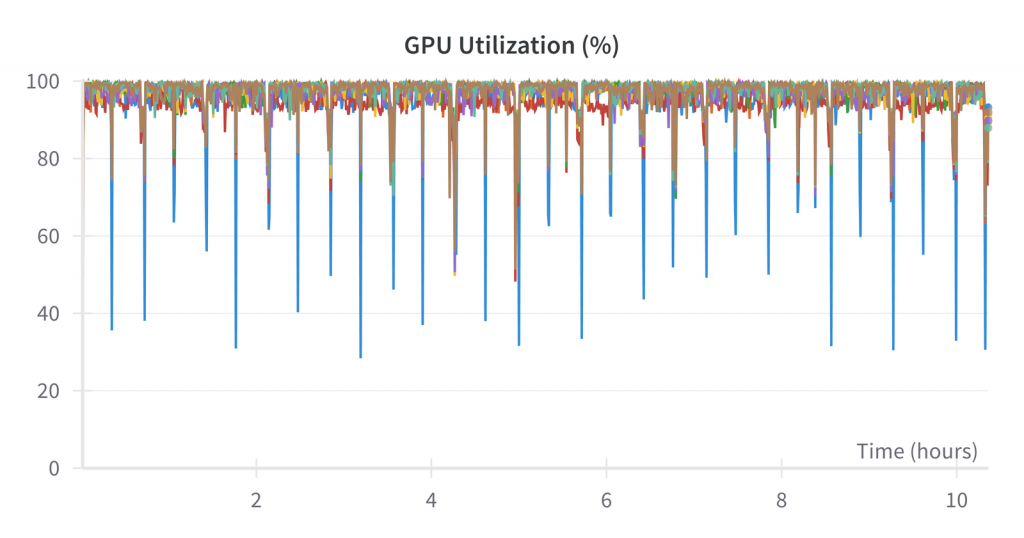
如上图所示,GPU的利用率在整个过程中接近 100%。最大的向下峰值(蓝色)是 8 个GPU中的第一个。
最后,H100s 的功耗约为 625 瓦:
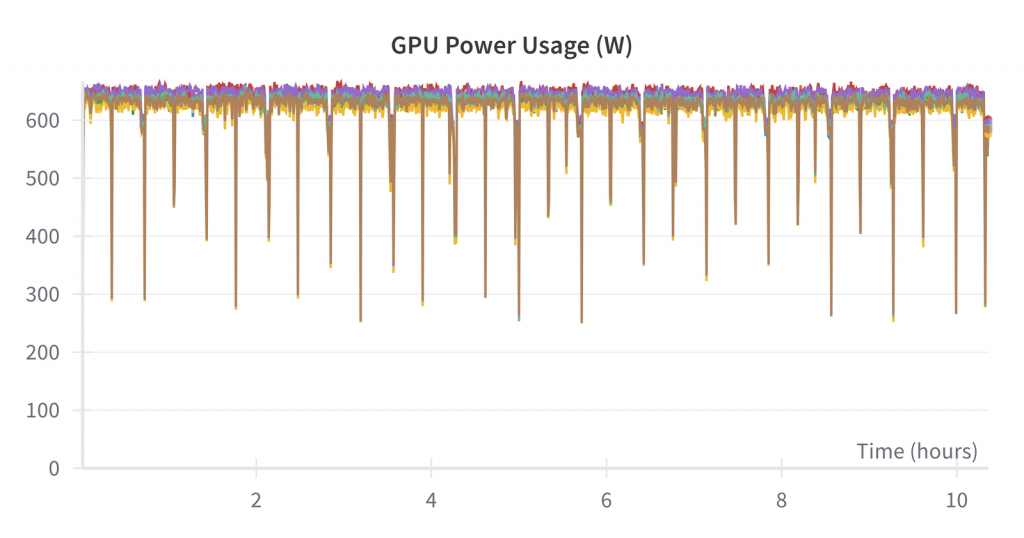
这意味着这次运行所用的总电量约为 625 瓦 × 10.5 小时 × 8 个 GPU × 1 个节点 ~ 50 千瓦时。
训练完成后,完全训练好的模型的检查点大小为 8.6 GB,现已准备好用于推理和部署(见下文)。
Fintuning MPT-30B
刚刚,我们在单个 H100×8 节点上预训练了 MPT-760m。现在,我们对MPT-30B模型进行微调,并展示使用2个节点(即多节点)的结果。(它也可以在4个节点上工作。)
获取模型
虽然微调所需的数据通常远小于预训练所需的数据,但所使用的模型可能会大得多。这是因为模型已经过预训练,意味着所需的计算量相对较少。
因此,我们能够从上面完整的预训练中的 MPT-760m 升级到具有 300 亿参数的 MPT-30B 模型的微调,同时保持几个小时的运行时间。
MPT-30B 的初始大小为 56 GB,下面的微调脚本会自动下载它。微调后,最终检查点在磁盘上的大小为 335 GB。
YAML文件
LLM Foundry的设置使得从用户的角度来看,微调与预训练非常相似。与上面一样,我们主要使用默认的 YAML 值,这次是从这里获取的,但现在做出以下更改:
run_name: <run name>
global_train_batch_size: 96
loggers:
wandb: {}
save_folder: /mnt/nick_mpt_8t/finetune/multinode/\
mpt-30b-instruct/checkpoints/{run_name}
save_interval: 999ep日志记录到 Weights and Biases 与预训练类似。这次我们在 YAML 中给了 run name。另一个必要的更改是全局训练批次大小必须可以被 GPU 总数整除,这里对于 2 个节点来说是 16。使用的值非常接近原始 YAML 的默认值 72。
由于现在每个检查点的大小为 335 GB,我们现在将它们直接保存到共享硬盘而不是机器的硬盘上。然而,这带来了一个关于符号链接的问题,在下面的说明中进行了更多讨论,这意味着保存间隔必须设置为一个较大的值。
最后,我们注释掉了原始 YAML 中给出的 ICL 模型评估任务,因为它们需要进一步设置。在训练期间,仍然会计算evaluation set上的loss、熵和 perplexity。
运行 finetuning
现在微调已准备就绪,并通过composer命令的多节点版本进行调用:
time composer \
--world_size 16 \
--node_rank $NODE_RANK \
--master_addr 10.1.2.3 \
--master_port 7501 \
/llm-foundry/scripts/train/train.py \
$SD/yamls/finetune/mpt-30b-instruct_multinode.yaml \
2>&1 | tee /llm-own/logs/finetune/multinode/\
${RUN_NAME}_run_finetuning.log这样做很方便,因为可以在每个节点上执行,从而实现多节点的训练,无需使用像 Slurm 这样的工作负载管理器,只要节点之间以及共享硬盘之间能够相互访问即可。
composer 命令会调用 PyTorch Distributed。在参数中,–world_size 表示 GPU 的总数,–node_rank 是每个节点的排名,例如 0、1、2 等,其中 0 是主节点,–master_addr 是主节点的私有 IP(在 GUI 机器详细信息页面上可见),–master_port 需要在每个节点上可见,我们使用各种环境变量以便在每个节点上执行相同的命令。YAML 文件获取了所有其他设置,并放置在共享硬盘上,因此我们只需要编辑一次。
节点 0 上的命令会等待在所有节点上发出命令,然后使用完全分片数据并行(FSDP)设置,在节点之间分布式运行模型训练。
注意:关于将检查点的保存间隔更改为 999 ep(999 个周期),这是一个临时解决方案:在我们当前的基础设施中,共享磁盘不支持符号链接。但是,MosaicML Repo 在其代码中使用了符号链接来指向最新的模型检查点。在可能存在许多检查点的情况下,这通常很好用,但在这里,它会导致在第一次保存检查点时运行中断,并出现错误提示“不支持符号链接”。我们可能需要分叉存储库并更改代码,或者提出一个 PR,使符号链接的使用成为可选的,但这可能需要在代码库的多个位置进行更改。相反,我们将保存间隔设置为大量的周期数,以便仅在运行结束时保存模型检查点。这样,当符号链接失败时,除了进程的零退出代码外,不会因失败而丢失任何内容。但这确实使我们的运行容易在结束前失败而丢失,并且也失去了查看中间检查点的能力,但我们的运行并非处于生产关键环境。在将云基础设施与AI/ML软件结合使用时,遇到此类限制并解决或绕过它们是处理大规模实际端到端问题的典型情况。
微调运行的结果
微调没有输出模型的 FLOPS 利用率,但我们可以看到与预训练类似的各种其他指标:
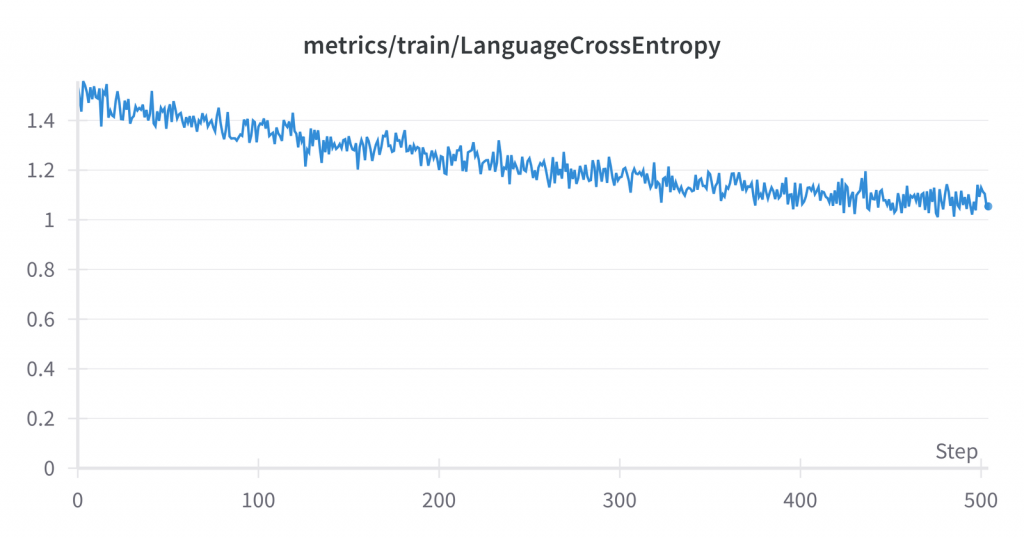
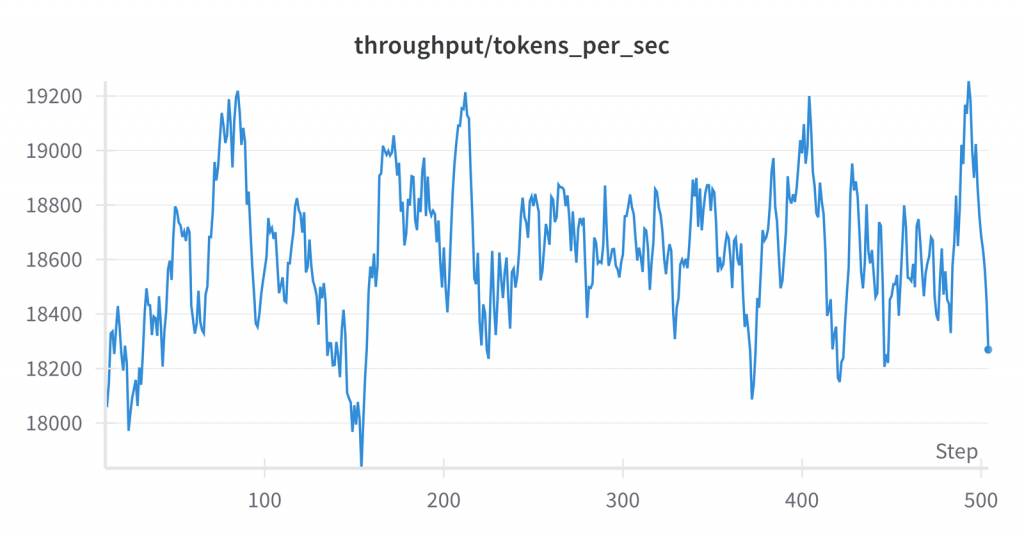
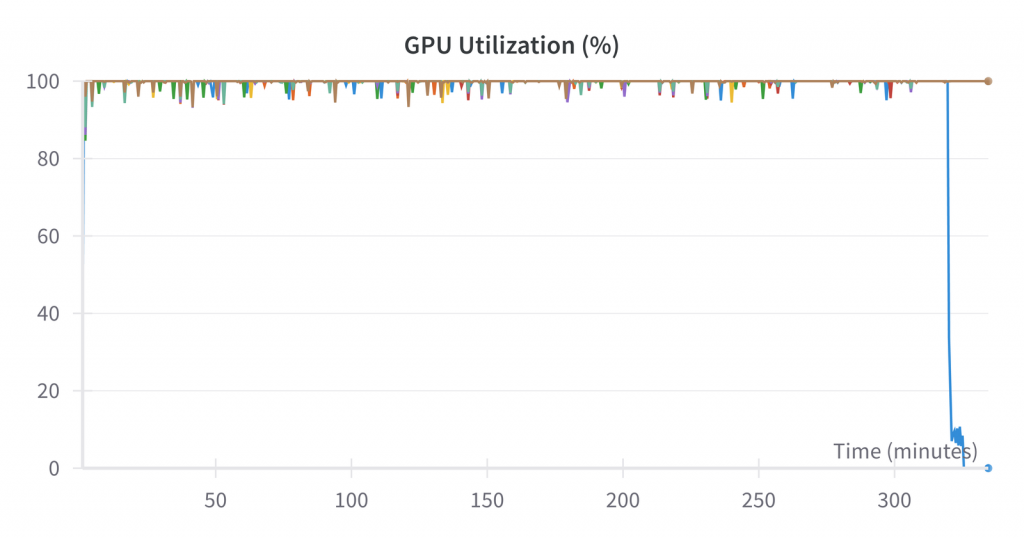
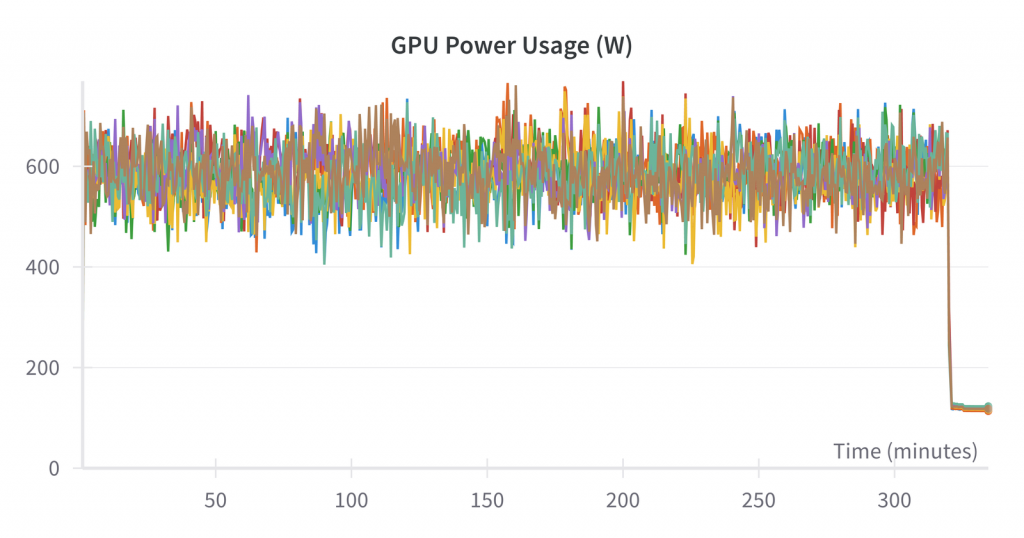
运行结束后,我们在共享硬盘上得到了最终的 335 GB 检查点。
有了这个检查点,我们就可以开始对我们预训练和微调后的模型进行推理和部署了。
推理和部署
经过预训练或微调后的模型包含一些额外的信息,如优化器状态等,这些信息对于在新未见数据上进行推理时并不需要。
因此,LLM Foundry 仓库中包含了一个脚本,用于将训练过程中的模型检查点转换为更小、更优化的 Hugging Face 格式,以便进行部署。
我们对预训练的 MPT-760m 和微调的 MPT-30B 的命令如下:
time python \
/llm-foundry/scripts/inference/convert_composer_to_hf.py \
--composer_path $SD/pretrain/single_node/node$NODE_RANK/\
mpt-760m/checkpoints/$RUN_NAME/$CHECKPOINT_NAME \
--hf_output_path $SD/pretrain/single_node/node$NODE_RANK/\
mpt-760m/hf_for_inference/$RUN_NAME \
--output_precision bf16 \
2>&1 | tee /llm-own/logs/pretrain/single_node/\
${RUN_NAME}_convert_to_hf.log
time python \
/llm-foundry/scripts/inference/convert_composer_to_hf.py \
--composer_path $SD/finetune/multinode/\
mpt-30b-instruct/checkpoints/$RUN_NAME/$CHECKPOINT_NAME \
--hf_output_path $SD/finetune/multinode/\
mpt-30b-instruct/hf_for_inference/$RUN_NAME \
--output_precision bf16 \
2>&1 | tee /llm-own/logs/finetune/multinode/\
${RUN_NAME}_convert_to_hf.log这些操作将磁盘上的模型大小从检查点的 8.6 GB 和 335 GB 减小到 1.5 GB 和 56 GB。对于微调的情况,我们看到转换后的 MPT-30B 模型大小与流程开始时下载的原始模型相同。这是因为微调保留了模型的原始架构,但更新了权重。
虽然占用的磁盘空间已经减少,但实际上,由于转换后的模型同时以.bin 和.safetensors 格式输出,因此实际大小是上述数字的两倍,即 3 GB 和 112 GB。
(我们还可以顺便注意到,这两个模型的大小之比大致等于它们参数数量之比:300 亿/7.6 亿≈40。)
转换后,我们可以通过传入用户输入并使用存储库的生成器脚本来查看它们的响应,从而“部署”模型以运行推理。
time python \
/llm-foundry/scripts/inference/hf_generate.py \
--name_or_path $SD/pretrain/single_node/node$NODE_RANK/\
mpt-760m/hf_for_inference/$RUN_NAME \
--max_new_tokens 256 \
--prompts \
"The answer to life, the universe, and happiness is" \
"Here's a quick recipe for baking chocolate chip cookies: Start by" \
2>&1 | tee /llm-own/logs/pretrain/single_node/\
${RUN_NAME}_hf_generate.log
time python \
/llm-foundry/scripts/inference/hf_generate.py \
--name_or_path $SD/finetune/multinode/mpt-30b-instruct/\
hf_for_inference/$RUN_NAME \
--max_new_tokens 256 \
--prompts \
"The answer to life, the universe, and happiness is" \
"Here's a quick recipe for baking chocolate chip cookies: Start by" \
2>&1 | tee /llm-own/logs/finetune/multinode/\
${RUN_NAME}_hf_generate.log
这些响应看起来没问题。
这些是来自MPT-760m的响应,已截断到字符限制:
######################################################################### The answer to life, the universe, and happiness is: the only path which matters. The book of the year has a special place in everyone’s heart. It can be said only as a metaphor. As we look for the meaning of life and happiness, some things that come from the heart come from the mind too. Like in this case, that something which is born with the human body begins to grow, and begins to feel the way you do, your heart grow and develop, with the help of the Holy Spirit. The world of the spirit and the universe of matter, and the eternal reality which exists in all the universe and the human body, begin to grow and to grow, and at the same time grow and to develop, to develop and to develop. This is very good news because we can come to the heart and can find our place in the cosmos, and we become a soul. We can come to know the true, and in truth, we can reach the truth about our existence. We can come to find peace about our life, and we can find our place in the universe, and we grow. And we can find our place in the other side, and all have the same power. How far have the people of Earth experienced transformation, but did not know ######################################################################### Here’s a quick recipe for baking chocolate chip cookies: Start by pouring the nuts into the butter or buttermilk and water into the pan and then sprinkle with the sugars. Put the oven rack in the lower half of the oven and spread out 2 sheets of aluminum foil about 1 cm above the pan, and then put each rectangle in the preheated oven for 10 minutes. Once done, remove the foil. While the nuts are cooking, put 1 tsp of maple syrup in a small pan with the sliced zucchini and stir well. Cook together with the juices, stirring occasionally. The juices are a rich syrup which you may add just prior to baking. Once the nuts are done, add 2 tsp of melted butter, and combine just before adding the flour mixture. You may need a little more than half milk if you like yours sweet. Transfer the batter to the baking dish and bake for 40 minutes, stirring only once every 10 minutes. You may bake the cookies for about an hour after baking. If you are using a pan with a metal rack, place the baking sheet on a high rack and pour the nuts/butter on top of the pan. The nuts will rise like a candy bar after taking a few minutes to cook on a tray. In another bowl mix together the flour and baking powder #########################################################################
如何准确量化一个大型语言模型(LLM)对用户提示的响应有多好,仍然是一个研究问题。因此,尽管“响应看起来没问题”似乎是一种相当粗略的检查,但实际上,它是我们的端到端流程有效的一个验证。
现在我们的模型运行完成了!
还有什么改进空间?
我们的主要目标是展示多节点LLM以端到端的方式工作。在这个过程中,我们也遇到了各种问题、解决方案、内部反馈以及产品迭代改进,但在这里并未展示。
未来在大规模AI工作中还有许多可以改进的地方,这些改进既针对这个特定案例,也适用于更普遍的情况:
- 使用XFormers和FP8:上文设置部分提到的这些可选安装可能提供一些额外的加速。
- YAML优化细节:对于H100s来说,最佳批处理大小可能与GitHub存储库中的默认值略有不同。
- 减少手动步骤:这里的许多步骤都可以实现自动化,例如在每个节点上运行相同的容器设置,然后执行命令。
- 符号链接:解决共享驱动器符号链接问题将使处理检查点更加方便。
- 更多的提示和响应:我们在这里只是简短地使用了最终结果的模型,检查了一些响应是否有意义。对于生产工作来说,进行更多的检查会更加谨慎,例如,与基线模型的输出进行实证比较,以及模型响应对于用户的适用性和安全性。
结论与下一步计划
我们已证明,使用单个或多个 H100×8 GPU 节点,可以在 DigitalOcean 的 Paperspace(PS by DO)GPU 云平台上运行大语言模型(LLMs)的预训练和微调。
DigitalOcean 的 Paperspace(PS by DO)结合了易用性、使用简单性、GPU选择多样性、可靠性和可扩展性以及全面的客户支持,是希望进行AI工作的企业和其他客户的理想选择,无论是进行预训练、微调还是部署现有模型。
除了这里展示的大语言模型外,这套端到端的流程,同样适用于其他常见 AI 领域(如计算机视觉和推荐系统)中的模型。
接下来,有些文档可能会有助于大家跑完预训练和微调:
- 使用DigitalOcean 的 Paperspace H100s:注册DigitalOcean的Paperspace,你将能快速用到本博客文章中使用的硬件、机器和软件。
- 查阅文档:有关使用 ML in a Box 进行深度学习和 NVIDIA H100 Tensor Core GPU的文档非常有用。
- 部署模型和Web应用程序:Paperspace Deployments允许将此处看到的经过训练的模型运行推理并部署到端点,该端点可以通过Web应用程序或其他接口进行访问。DigitalOcean已经有大量客户在使用Web应用程序,因此使用它们进行AI工作也非常合适。
- 获取官方技术支持:如果你需要跟官方咨询,或者申请更多的 GPU 资源,可以直接与 DigitalOcean 的中国区战略合作伙伴卓普云联系。如果你需要更多 GPU 资源,扫描下方二维码,也可以直接联系到 DigitalOcean 的工作人员来咨询。
OK,那么本篇教程就到这里。