DigitalOcean 的 PostgreSQL、MySQL、Redis、Kafka托管数据库,现已支持自定义指标收集功能
自定义数据库监测指标,可帮助你又话数据库性能、合理规划容量、快速排查问题。

近期,我们的几个托管数据库(PostgreSQL、MySQL、Redis和Kafka)引入了自定义数据指标功能(scrapable metrics)。这些指标使您更具体、更细致地了解数据库的性能,包括延迟、资源利用率和错误率。然后,您可以将这些指标导出到 Prometheus等监控平台中,增强可见性和监控能力。
该功能能够通过编程的方式访问指标端点,该功能公开的指标数量,是我们目前通过“insight”页面公开的指标数量的 20 倍。当然我们始终将简单易用性作为功能开发和版本升级的首要任务,确保客户无需构建自定义脚本即可访问这些指标。
监控数据库性能对于确保依赖它的应用程序的平稳运行至关重要。例如,一家多平台媒体公司的 Redis 数据库延迟突然增加,影响了用户体验。为了诊断这个问题,他们利用了 DigitalOcean 托管数据库提供的自定义数据指标功能。
这些指标跟踪了特定 Redis 命令的使用频率,例如用于数据检索的“GET”,用于数据存储的“SET”,用于基于模式的搜索的“KEYS*”,以及用于数据删除的“DEL”。分析这些指标有助于他们确定根本原因,并快速实施修复以恢复正常应用程序性能。
在我们的产品文档中了解如何访问自定义数据指标(scrapable metrics),以及您可以访问数据库的哪些指标,点击以下链接即可访问对应文档:
通过“insight”页面访问标准指标
您可以直接在数据库仪表板页面的“insight”页面上访问关于您的集群和数据库的基本指标:

图:洞察页面截图
要查看某个数据库集群的以上性能指标,请单击数据库的名称以转到其概览页面,然后点击“insight”页面。例如,以下是 PostgreSQL 数据库的连接洞察视图:
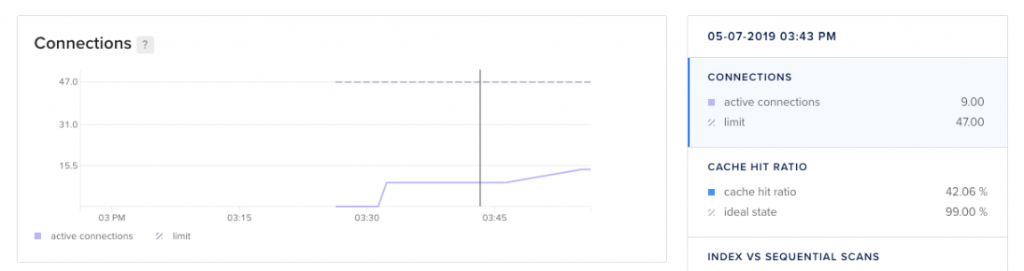
图:指标截图
通过监控您的集群和数据库的指标,您可以:
- 优化数据库性能:新的自定义数据指标功能为优化数据库性能提供了宝贵的数据。基于延迟指标可识别需要改进的特定查询。提高索引和缓存命中的效率以管理数据库负载。
- 合理规划容量:利用自定义数据指标功能(如资源使用模式、增长趋势和峰值工作负载)来做出关于容量要求和规划的明智决策。
- 快速排查问题:方便访问数据库操作和性能指标对于有效的故障排查至关重要。如果出现问题,您现在可以使用这些可自定义的指标来帮助确定根本原因,无论是查询瓶颈、资源问题还是连接问题。凭借这些信息,您可以快速诊断并解决问题,从而专注于开发以客户为中心的功能。
要了解更多关于监控数据库和集群性能的信息,请参阅以下产品文档:
PostgreSQL:
MySQL:
Redis:
Kafka:
通过创建 DigitalOcean 账户,来体验一下更新后的自定义数据指标监测功能吧。如果你希望咨询更多云服务方案,或希望从其它云服务迁移到 DigitalOcean,请访问DigitalOcean 中国独家战略合作伙伴卓普云AI Droplet 咨询。